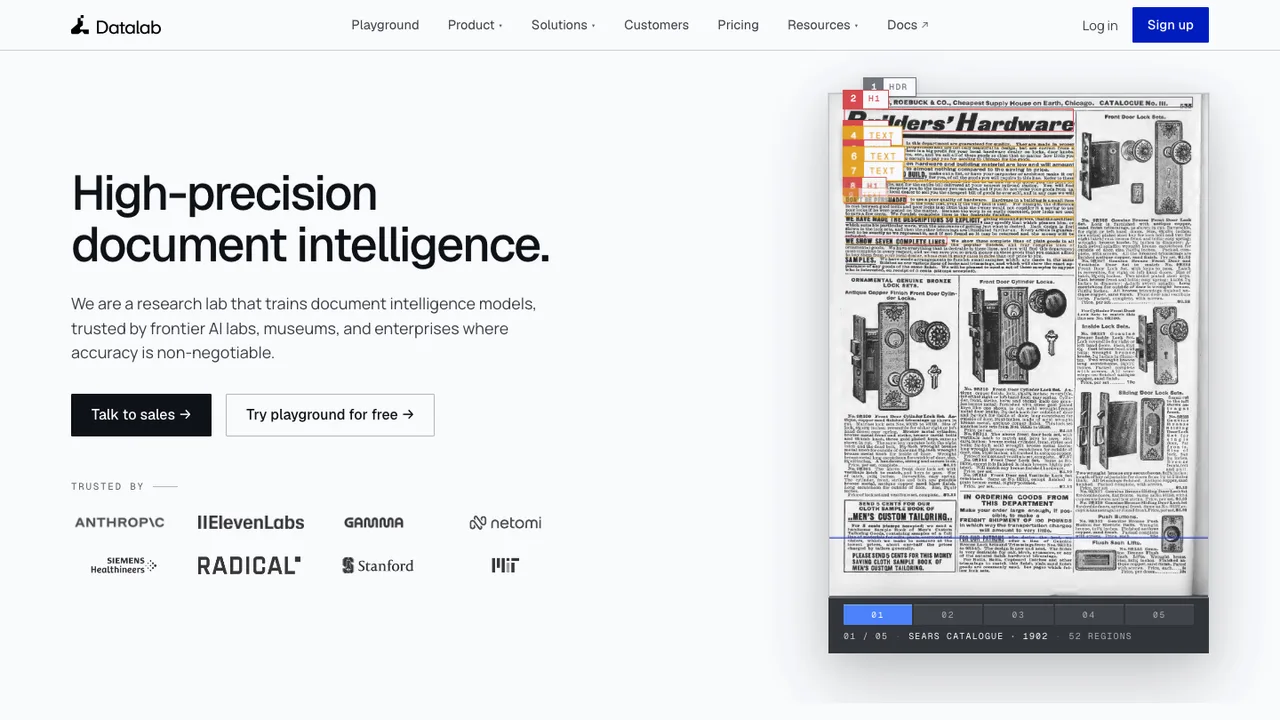
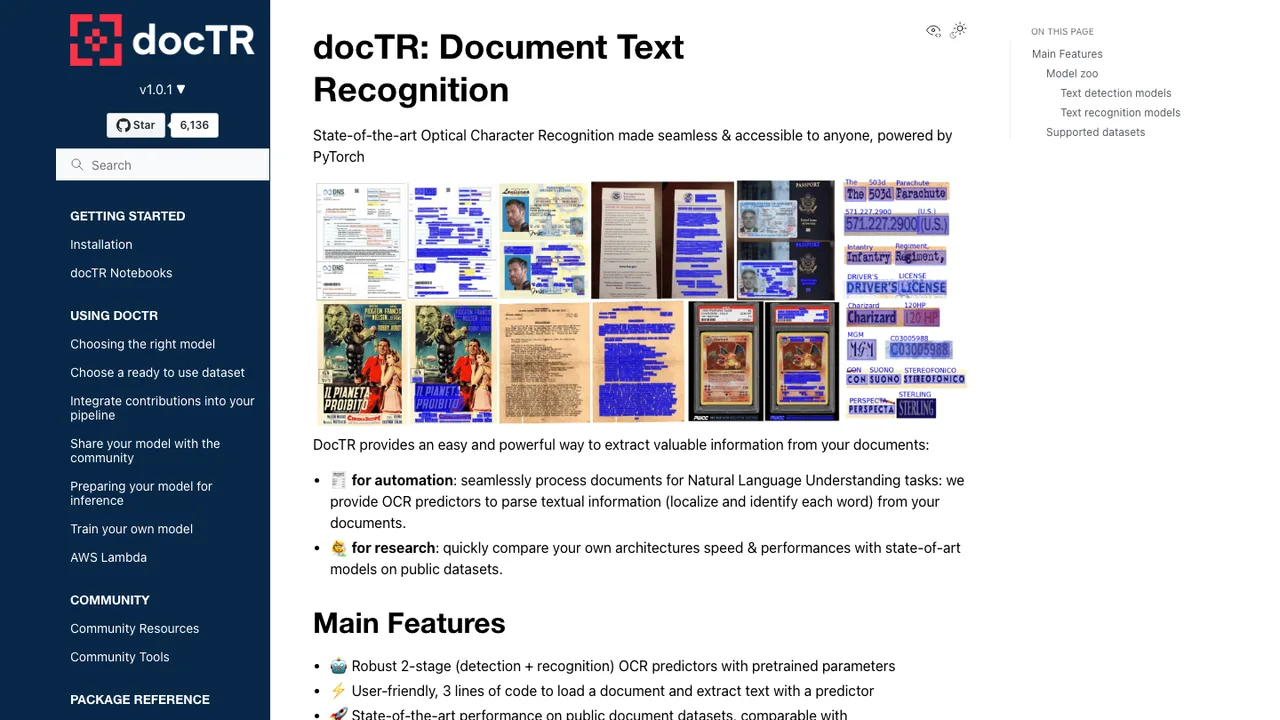
One integrated converter, or a few sharper tools chained together: that choice comes before any head-to-head comparison. Docling hides PDF parsing, OCR, layout detection, and table extraction behind a single document model, which is convenient until one stage misbehaves on your worst files. Some replacements keep that all-in-one shape: MinerU pairs a vision-language model with OCR to handle PDFs, Office files, scans, and handwriting, converting formulas to LaTeX and tables to HTML. Others deliberately do less, like Tesseract, a pure OCR engine, or docTR, a two-stage detection-and-recognition library you wire into your own pipeline.
Where replacements differ most is layout fidelity, not raw text extraction. Reading order, merged cells, captions, and multi-column pages are the parts that break silently, so weigh how each tool reconstructs structure. Surya ships explicit layout analysis with reading order and table recognition across more than 90 languages, while PaddleOCR targets LLM-ready output with document parsing for text, tables, formulas, and charts. If your documents are largely scanned or multilingual, an OCR-first tool with strong language coverage will usually beat a general parser tuned for born-digital reports.
Because these are libraries and services rather than hosted accounts, migration is a reprocessing project. Inventory every place that consumes Docling's Markdown, JSON, page numbers, and image references, run a representative sample through the candidate, and diff the output before you commit. Expect to rebuild search indexes and embeddings, since different chunk boundaries and table serialization change the text you feed downstream. Keeping your source files as the system of record makes this switch, and any future one, far less painful.