
OCR library for document text detection and recognition with PyTorch and TensorFlow 2
- Stars6.1k
- Forks650
- Open Issues31
Apache-2.0
- Python
- Dockerfile
- Makefile
About docTR
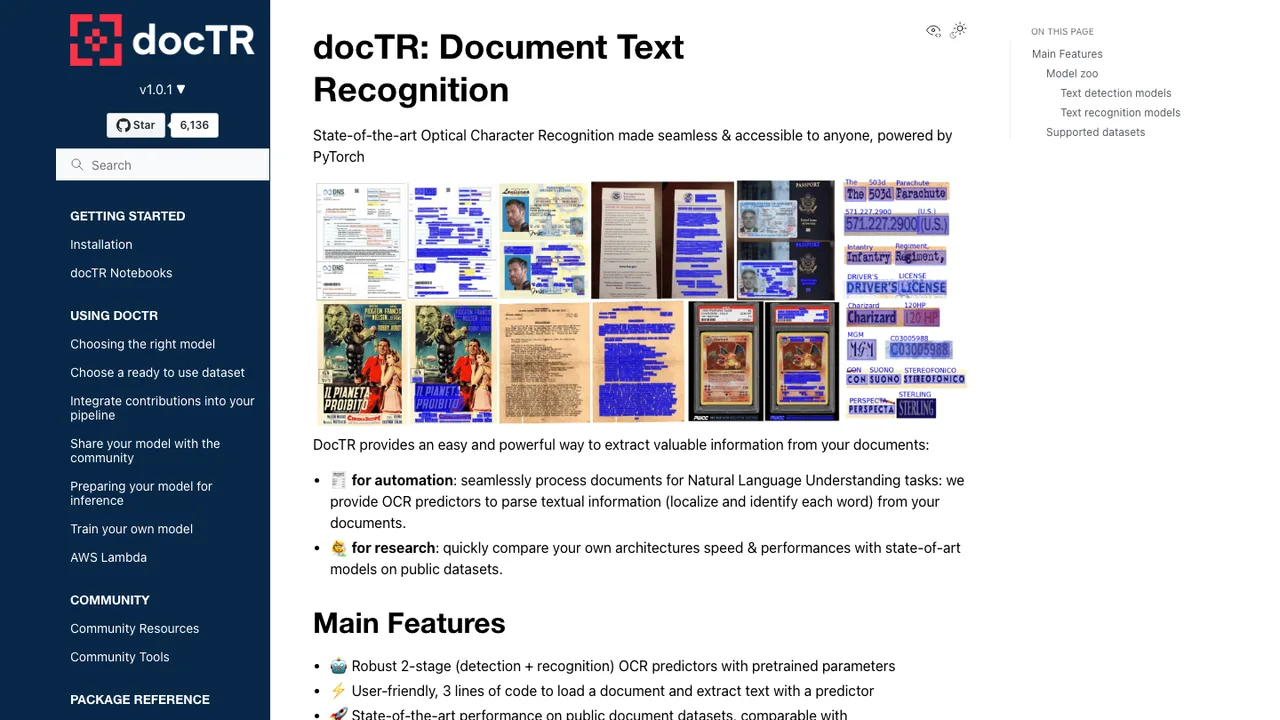
docTR is an optical character recognition library for parsing textual information from documents. It handles the core OCR workflow of locating words and identifying the characters in each word, with pretrained models for document analysis.
It uses a two-stage approach - text detection and text recognition - and lets you choose the architecture for each step. It also includes a KIE predictor, supports PDF and image inputs, and can export results as JSON. Example usage covers local analysis and an HTTP OCR endpoint.
docTR ships as a Python package, can be run in Docker, and is licensed under Apache 2.0. It has implementations powered by PyTorch and TensorFlow 2, with installation shown through pip and editable source installs. The project is maintained by Mindee.
Key features
- Two-stage OCR with text detection and text recognition
- Pretrained models for document analysis
- KIE predictor for structured predictions
- PDF and image input support
- Result export and visualization
Details
- First released
- 2021
- License
- Apache 2.0
- Platforms
- Linux · Docker · CLI
- Deployment
- self-hostable · docker
- Language
- Python
- Frameworks
- PyTorch · TensorFlow 2