
OCR and document analysis model for 90+ languages with layout, reading order, and tables
- Stars20.8k
- Forks1.5k
- Open Issues171
Apache-2.0
- Python
- HTML
- JavaScript
About Surya
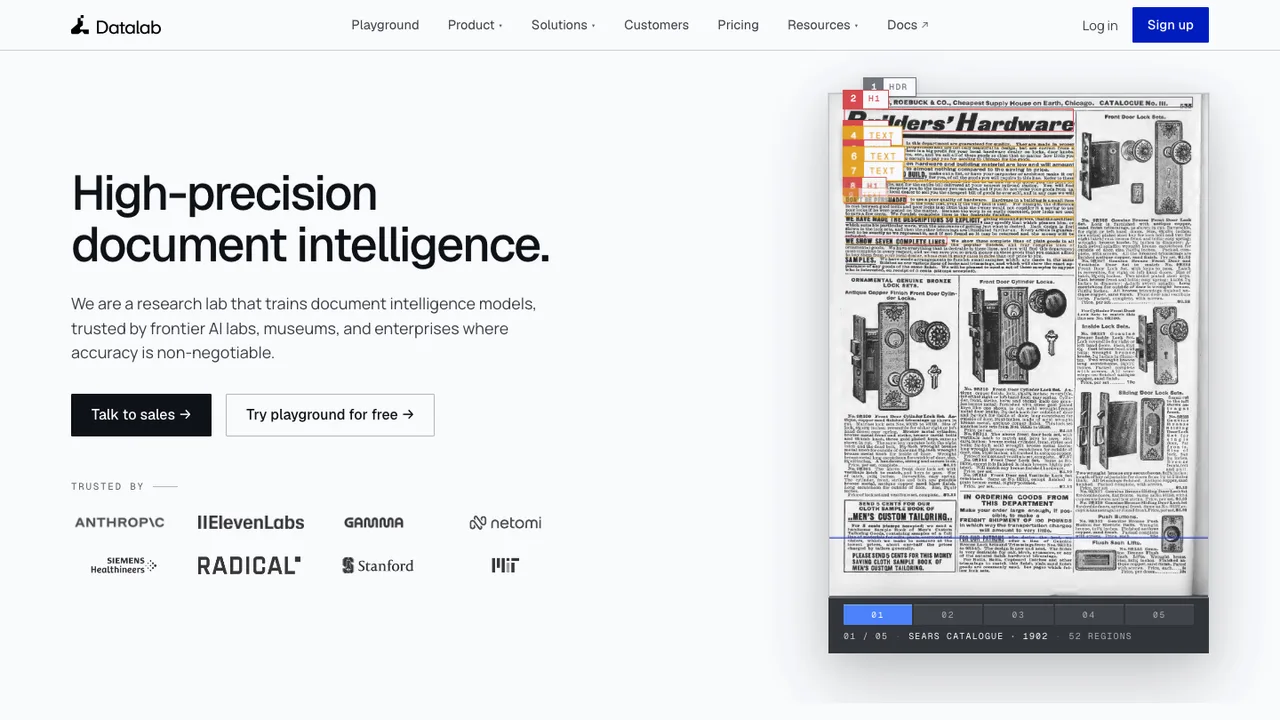
Surya is a 650M parameter OCR model for document intelligence. It turns document images into text and structured page data, including detected text, bounding boxes, and page-level OCR results.
It adds layout analysis for tables, images, headers, and reading order, plus table recognition for rows and columns. It also includes smaller models for line-level text detection and OCR error detection, and runs inference through a vLLM backend on NVIDIA GPUs or llama.cpp on CPU and Apple Silicon.
Datalab ships a managed platform that runs Surya and Chandra, alongside a public playground and commercial model licensing. The code is licensed under Apache 2.0, while the model weights use a modified AI Pubs Open Rail-M license. The project can be run locally from source, and the managed platform is an optional hosted service.
Key features
- 650M parameter OCR model
- Layout analysis with reading order
- Table recognition for rows and columns
- Multilingual OCR across 90+ languages
- Line-level text detection and OCR error detection
Details
- First released
- 2024
- Platforms
- CLI · Web
- Deployment
- self-hostable · cloud
- License
- Apache 2.0
- Model weights
- Modified AI Pubs Open Rail-M
- Languages
- 91