
Metadata service for collecting, aggregating, and visualizing data lineage and provenance
- Stars2.2k
- Forks400
- Open Issues244
Apache-2.0
- Java
- TypeScript
- Python
About Marquez
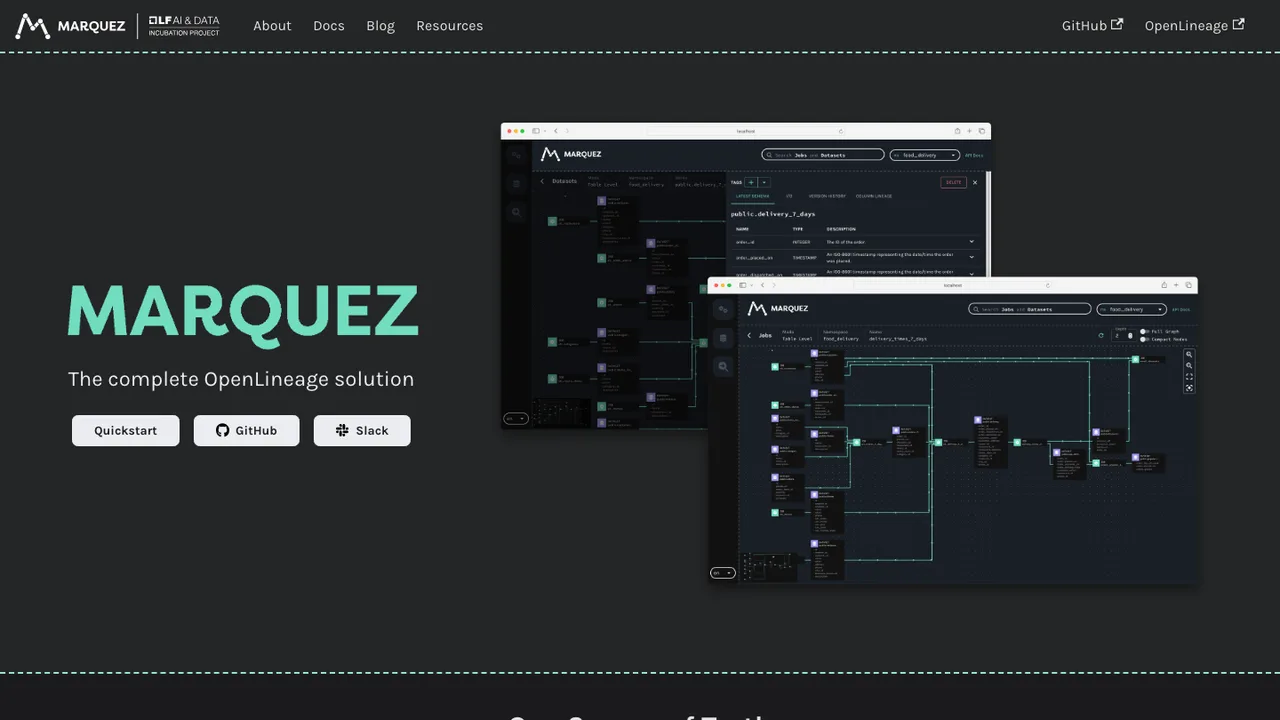
Marquez is an open source metadata service for collecting, aggregating, and visualizing a data ecosystem's metadata. It maintains the provenance of how datasets are consumed and produced, and gives global visibility into job runtime and how often datasets are accessed. It was released and open sourced by WeWork.
The service collects dataset, job, and run metadata using OpenLineage, of which it is the reference implementation. A core API stores metadata in PostgreSQL, a web UI shows dependencies between jobs and the datasets they produce and consume through a lineage graph, and HTTP and GraphQL endpoints are available. By default the HTTP API requires no authentication or authorization.
Marquez is an LF AI & Data Foundation Graduated project. The easiest way to start is with Docker, and it can also be built from source with Java 17 and PostgreSQL 14. Helm charts are provided for Kubernetes deployments.
Key features
- Collects dataset, job, and run metadata
- Tracks how datasets are consumed and produced
- Visualizes job dependencies in a lineage graph
- Reference implementation of the OpenLineage standard
- HTTP and GraphQL APIs over a PostgreSQL store
Details
- On GitHub since
- 2018
- Language
- Java, TypeScript, Python
- Database
- PostgreSQL 14
- Standard
- OpenLineage reference
- Governance
- LF AI & Data Graduated project
- License
- Apache-2.0