
Node.js library for web scraping and browser automation
- Stars23.8k
- Forks1.4k
- Open Issues171
Apache-2.0
- TypeScript
- MDX
- JavaScript
About Crawlee
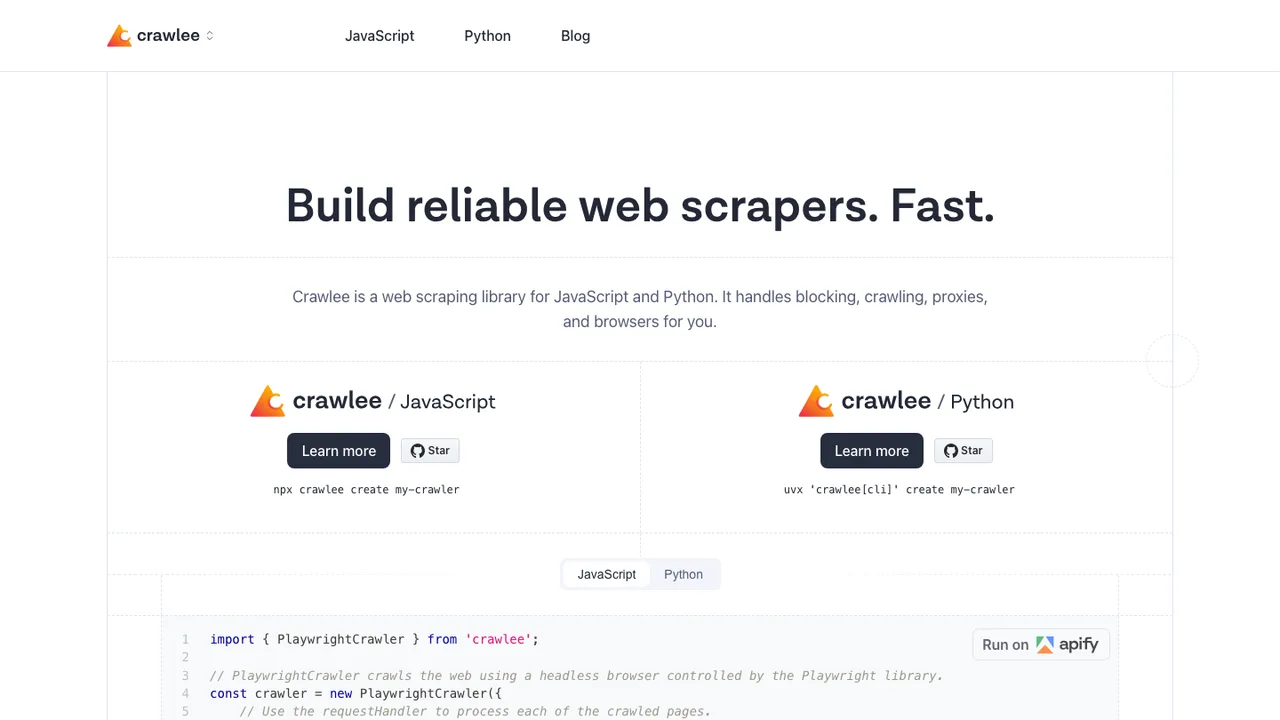
Crawlee is a web scraping and browser automation library for Node.js, written in JavaScript and TypeScript. It builds reliable crawlers that follow links, scrape data, and store results to disk or cloud, covering both HTTP and headless browser crawling through one interface.
A persistent request queue, pluggable storage, automatic scaling to system resources, proxy rotation, and session management are built in. HTTP crawling uses Cheerio or JSDOM, while browser crawling drives Playwright or Puppeteer in headless or headful mode, with anti-blocking defaults to mimic real users.
Crawlee is developed by Apify and released under the Apache License 2.0. It installs as an npm package, ships with a CLI scaffold, and has a separate Python version for Python users.
Key features
- One interface for HTTP and headless crawling
- Persistent request queue for link discovery
- Proxy rotation and session management
- Playwright and Puppeteer, headless or headful
- Anti-blocking defaults to mimic real users
Details
- First released
- 2016
- Platforms
- Library · CLI
- Language
- TypeScript · JavaScript
- Origins
- Apify
- Install
- npm install crawlee
- License
- Apache-2.0