
Fast, elegant scraping and crawling framework for Go
Repository activity
- Stars25.3k
- Forks1.9k
- Open Issues194
License
Apache-2.0
Languages
- Go
- HTML
About Colly
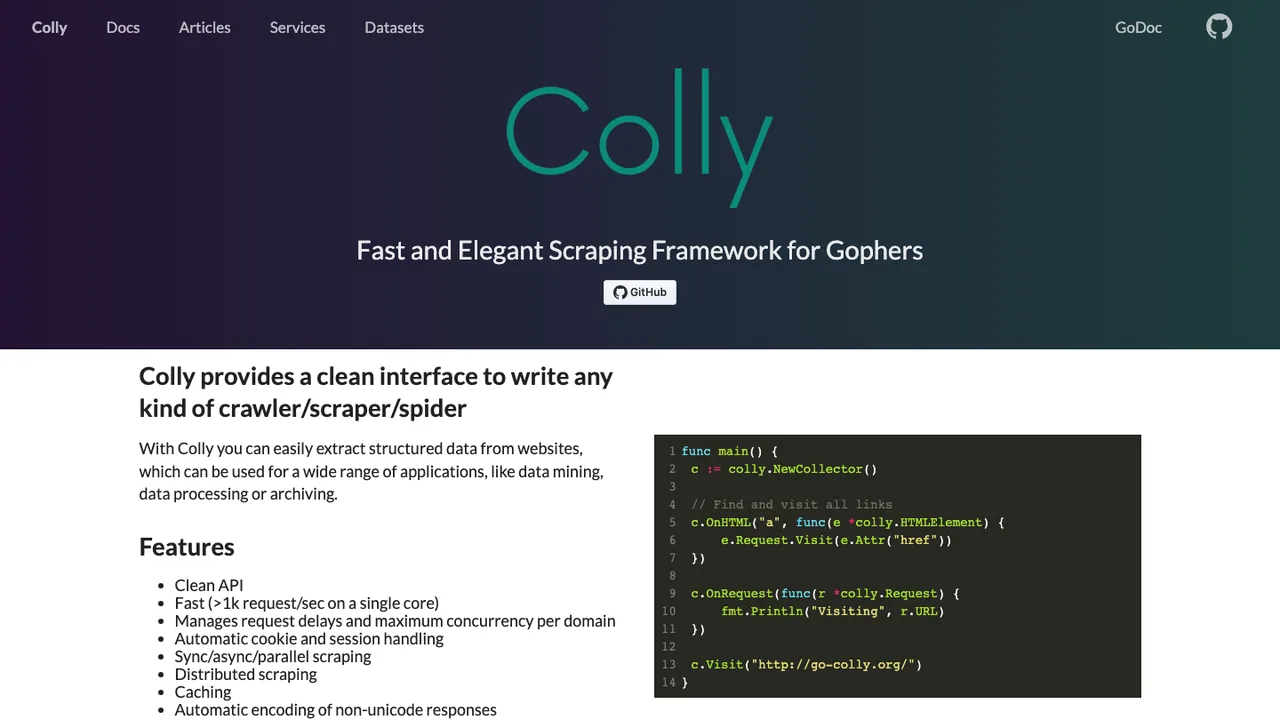
Colly is a Go framework for writing crawlers, scrapers, and spiders. It exposes a clean callback-based API for extracting structured data from websites, with uses spanning data mining, data processing, and archiving.
It manages request delays and maximum concurrency per domain, handles cookies and sessions automatically, and supports sync, async, and parallel scraping. Caching, automatic encoding of non-unicode responses, robots.txt handling, distributed scraping, and configuration via environment variables round out the feature set.
Colly is an open source Go library, installed with go get and used by many other scraping projects. It is released under the Apache License 2.0.
Key features
- Callback-based API for scrapers and crawlers
- Request delays and max concurrency per domain
- Automatic cookie and session handling
- Sync, async, and parallel scraping
- robots.txt support and distributed scraping
Details
- First released
- 2017
- Latest release
- v2.2.0 · 2025
- Language
- Go
- Install
- go get gocolly/colly/v2
- Deployment
- Library
- License
- Apache-2.0