
Open-source text-to-speech models with multilingual voice cloning and built-in watermarking
- Stars25.1k
- Forks3.3k
- Open Issues341
MIT
- Python
About Chatterbox
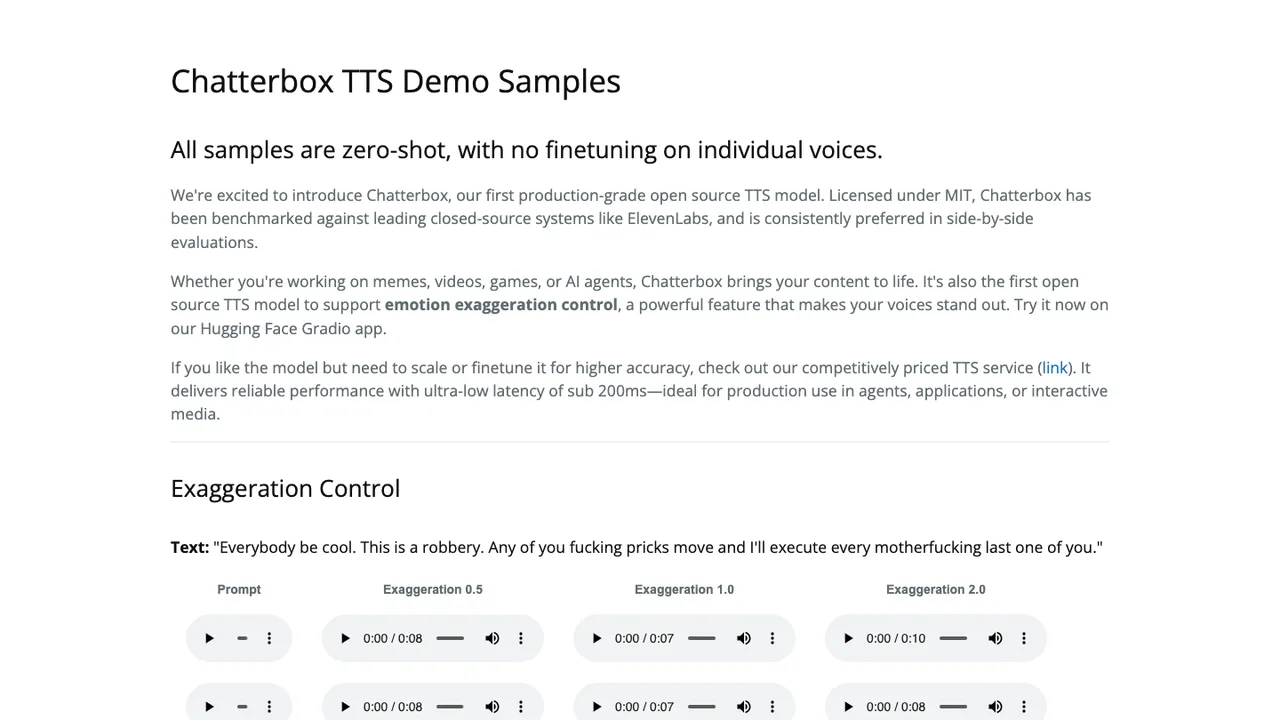
Chatterbox is a family of open-source text-to-speech models from Resemble AI. It turns text into speech for voice cloning, multilingual narration, and low-latency voice agents.
The multilingual model covers Arabic, Danish, German, Greek, English, Spanish, Finnish, French, Hebrew, Hindi, Italian, Japanese, Korean, Malay, Dutch, Norwegian, Polish, Portuguese, Russian, Swedish, Swahili, Turkish, and Chinese. Chatterbox Turbo is a 350M parameter model with native paralinguistic tags such as [cough], [laugh], and [chuckle], and it generates audio from a reference clip.
Chatterbox embeds Resemble AI's PerTh perceptual watermarker in every generated audio file, designed to survive MP3 compression and common editing while staying imperceptible. The code and models are published by Resemble AI; you can install it with pip as chatterbox-tts or run it from source for local, offline generation.
Key features
- Multilingual TTS across 23 listed languages
- Voice cloning from a reference audio clip
- Turbo model with native paralinguistic tags
- PerTh watermarking in generated audio
- Single Language Pack for language-specific finetunes
Details
- First released
- 2025
- Platforms
- Web · CLI
- Deployment
- self-hostable · offline-first
- Watermarking
- PerTh perceptual threshold
- Model size
- 0.5B · Turbo 350M
- Languages
- 23 listed languages