
Real-time distributed OLAP datastore for low-latency analytics on streaming and batch data
- Stars6.1k
- Forks1.5k
- Open Issues1.6k
Apache-2.0
- Java
- TypeScript
- Scala
About Apache Pinot
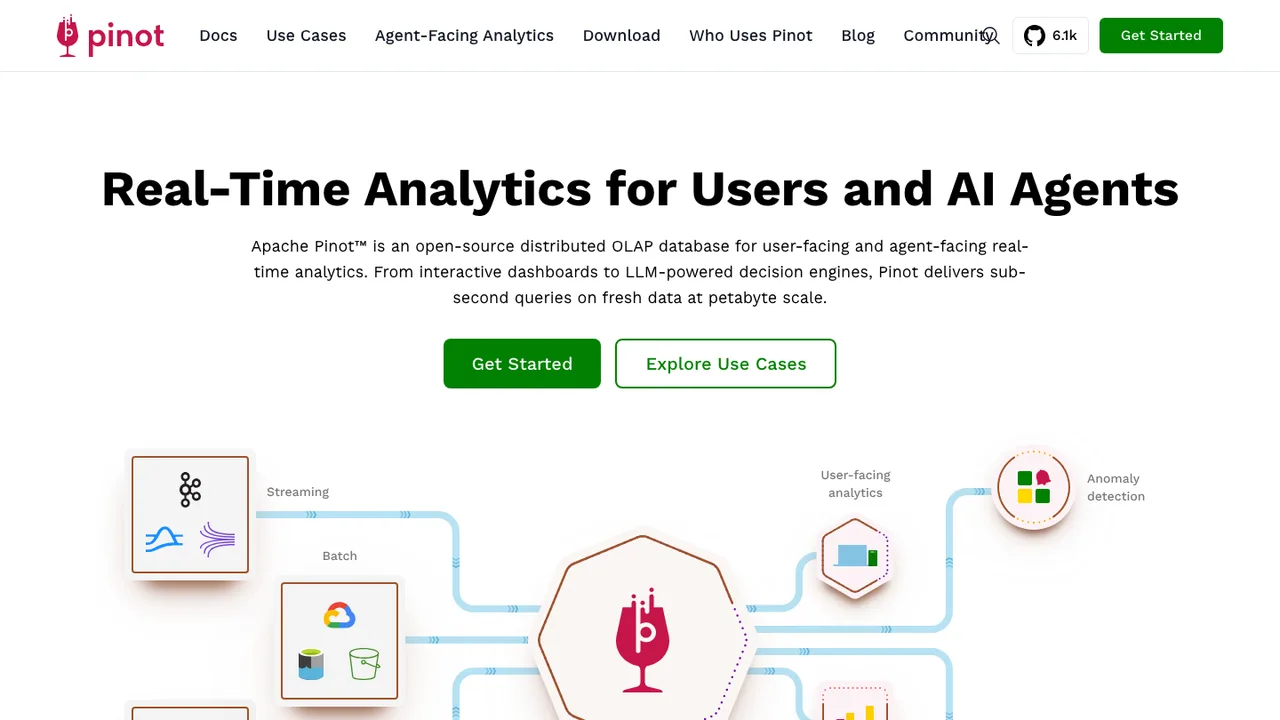
Apache Pinot is a real-time distributed OLAP datastore built for user-facing analytics that stay fast at high query volumes. It ingests batch data from HDFS, Amazon S3, Azure ADLS, and Google Cloud Storage, plus streams from Kafka, Pulsar, and Kinesis, and answers queries on fresh data with low latency.
Queries run through standard SQL via a built-in editor and a REST API. Pinot filters and aggregates petabyte data sets in milliseconds, supports arbitrary fact-dimension and fact-fact joins, and upserts during real-time ingestion. Pluggable indexes cover timestamp, inverted, StarTree, Bloom filter, range, text, JSON, and geospatial lookups.
Built at LinkedIn and Uber, Pinot is horizontally scalable and fault-tolerant, deploys on Kubernetes via a Helm chart, and connects to Trino and Apache Superset.
Key features
- Standard SQL through a built-in query editor and REST API
- Petabyte-scale filtering and aggregation in milliseconds
- Arbitrary fact-dimension and fact-fact joins
- Upsert during real-time ingestion
- Pluggable indexing for timestamp, text, JSON, and geospatial queries
Details
- First released
- 2014
- Type
- Distributed OLAP datastore
- Language
- Java
- Storage
- Batch and streaming ingest
- Deployment
- Self-hosted · Docker · Kubernetes
- Governance
- Apache Software Foundation